




Control Products
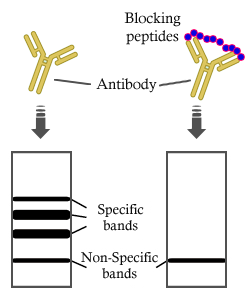
製品説明
*The optimal dilutions should be determined by the end user. For optimal experimental results, antibody reuse is not recommended.
*Tips:
WB: For western blot detection of denatured protein samples. IHC: For immunohistochemical detection of paraffin sections (IHC-p) or frozen sections (IHC-f) of tissue samples. IF/ICC: For immunofluorescence detection of cell samples. ELISA(peptide): For ELISA detection of antigenic peptide.
引用形式: Affinity Biosciences Cat# DF12011, RRID:AB_2844816.
折りたたみ/展開
adrenal gland protein AD-005; CCR4 NOT transcription complex subunit 1 isoform b; CCR4-associated factor 1; hNOT1; Negative regulator of transcription subunit 1 homolog; NOT1 (negative regulator of transcription 1 yeast) homolog; NOT1H;
免疫原
A synthesized peptide derived from human CNOT1, corresponding to a region within the internal amino acids.
Strongly expressed in brain, heart, thymus, spleen, kidney, liver, placenta and lung. Weakly expressed in skeletal muscle and colon.
- A5YKK6 CNOT1_HUMAN:
- Protein BLAST With
- NCBI/
- ExPASy/
- Uniprot
MNLDSLSLALSQISYLVDNLTKKNYRASQQEIQHIVNRHGPEADRHLLRCLFSHVDFSGDGKSSGKDFHQTQFLIQECALLITKPNFISTLSYAIDNPLHYQKSLKPAPHLFAQLSKVLKLSKVQEVIFGLALLNSSSSDLRGFAAQFIKQKLPDLLRSYIDADVSGNQEGGFQDIAIEVLHLLLSHLLFGQKGAFGVGQEQIDAFLKTLRRDFPQERCPVVLAPLLYPEKRDILMDRILPDSGGVAKTMMESSLADFMQEVGYGFCASIEECRNIIVQFGVREVTAAQVARVLGMMARTHSGLTDGIPLQSISAPGSGIWSDGKDKSDGAQAHTWNVEVLIDVLKELNPSLNFKEVTYELDHPGFQIRDSKGLHNVVYGIQRGLGMEVFPVDLIYRPWKHAEGQLSFIQHSLINPEIFCFADYPCHTVATDILKAPPEDDNREIATWKSLDLIESLLRLAEVGQYEQVKQLFSFPIKHCPDMLVLALLQINTSWHTLRHELISTLMPIFLGNHPNSAIILHYAWHGQGQSPSIRQLIMHAMAEWYMRGEQYDQAKLSRILDVAQDLKALSMLLNGTPFAFVIDLAALASRREYLKLDKWLTDKIREHGEPFIQACMTFLKRRCPSILGGLAPEKDQPKSAQLPPETLATMLACLQACAGSVSQELSETILTMVANCSNVMNKARQPPPGVMPKGRPPSASSLDAISPVQIDPLAGMTSLSIGGSAAPHTQSMQGFPPNLGSAFSTPQSPAKAFPPLSTPNQTTAFSGIGGLSSQLPVGGLGTGSLTGIGTGALGLPAVNNDPFVQRKLGTSGLNQPTFQQSKMKPSDLSQVWPEANQHFSKEIDDEANSYFQRIYNHPPHPTMSVDEVLEMLQRFKDSTIKREREVFNCMLRNLFEEYRFFPQYPDKELHITACLFGGIIEKGLVTYMALGLALRYVLEALRKPFGSKMYYFGIAALDRFKNRLKDYPQYCQHLASISHFMQFPHHLQEYIEYGQQSRDPPVKMQGSITTPGSIALAQAQAQAQVPAKAPLAGQVSTMVTTSTTTTVAKTVTVTRPTGVSFKKDVPPSINTTNIDTLLVATDQTERIVEPPENIQEKIAFIFNNLSQSNMTQKVEELKETVKEEFMPWVSQYLVMKRVSIEPNFHSLYSNFLDTLKNPEFNKMVLNETYRNIKVLLTSDKAAANFSDRSLLKNLGHWLGMITLAKNKPILHTDLDVKSLLLEAYVKGQQELLYVVPFVAKVLESSIRSVVFRPPNPWTMAIMNVLAELHQEHDLKLNLKFEIEVLCKNLALDINELKPGNLLKDKDRLKNLDEQLSAPKKDVKQPEELPPITTTTTSTTPATNTTCTATVPPQPQYSYHDINVYSLAGLAPHITLNPTIPLFQAHPQLKQCVRQAIERAVQELVHPVVDRSIKIAMTTCEQIVRKDFALDSEESRMRIAAHHMMRNLTAGMAMITCREPLLMSISTNLKNSFASALRTASPQQREMMDQAAAQLAQDNCELACCFIQKTAVEKAGPEMDKRLATEFELRKHARQEGRRYCDPVVLTYQAERMPEQIRLKVGGVDPKQLAVYEEFARNVPGFLPTNDLSQPTGFLAQPMKQAWATDDVAQIYDKCITELEQHLHAIPPTLAMNPQAQALRSLLEVVVLSRNSRDAIAALGLLQKAVEGLLDATSGADADLLLRYRECHLLVLKALQDGRAYGSPWCNKQITRCLIECRDEYKYNVEAVELLIRNHLVNMQQYDLHLAQSMENGLNYMAVAFAMQLVKILLVDERSVAHVTEADLFHTIETLMRINAHSRGNAPEGLPQLMEVVRSNYEAMIDRAHGGPNFMMHSGISQASEYDDPPGLREKAEYLLREWVNLYHSAAAGRDSTKAFSAFVGQMHQQGILKTDDLITRFFRLCTEMCVEISYRAQAEQQHNPAANPTMIRAKCYHNLDAFVRLIALLVKHSGEATNTVTKINLLNKVLGIVVGVLLQDHDVRQSEFQQLPYHRIFIMLLLELNAPEHVLETINFQTLTAFCNTFHILRPTKAPGFVYAWLELISHRIFIARMLAHTPQQKGWPMYAQLLIDLFKYLAPFLRNVELTKPMQILYKGTLRVLLVLLHDFPEFLCDYHYGFCDVIPPNCIQLRNLILSAFPRNMRLPDPFTPNLKVDMLSEINIAPRILTNFTGVMPPQFKKDLDSYLKTRSPVTFLSDLRSNLQVSNEPGNRYNLQLINALVLYVGTQAIAHIHNKGSTPSMSTITHSAHMDIFQNLAVDLDTEGRYLFLNAIANQLRYPNSHTHYFSCTMLYLFAEANTEAIQEQITRVLLERLIVNRPHPWGLLITFIELIKNPAFKFWNHEFVHCAPEIEKLFQSVAQCCMGQKQAQQVMEGTGAS
種類予測
Score>80(red) has high confidence and is suggested to be used for WB detection. *The prediction model is mainly based on the alignment of immunogen sequences, the results are for reference only, not as the basis of quality assurance.
High(score>80) Medium(80>score>50) Low(score<50) No confidence
研究背景
Scaffolding component of the CCR4-NOT complex which is one of the major cellular mRNA deadenylases and is linked to various cellular processes including bulk mRNA degradation, miRNA-mediated repression, translational repression during translational initiation and general transcription regulation. Additional complex functions may be a consequence of its influence on mRNA expression. Its scaffolding function implies its interaction with the catalytic complex module and diverse RNA-binding proteins mediating the complex recruitment to selected mRNA 3'UTRs. Involved in degradation of AU-rich element (ARE)-containing mRNAs probably via association with ZFP36. Mediates the recruitment of the CCR4-NOT complex to miRNA targets and to the RISC complex via association with TNRC6A, TNRC6B or TNRC6C. Acts as a transcriptional repressor. Represses the ligand-dependent transcriptional activation by nuclear receptors. Involved in the maintenance of embryonic stem (ES) cell identity.
Cytoplasm>P-body. Nucleus.
Note: NANOS2 promotes its localization to P-body.
Strongly expressed in brain, heart, thymus, spleen, kidney, liver, placenta and lung. Weakly expressed in skeletal muscle and colon.
Contains Leu-Xaa-Xaa-Leu-Leu (LXXLL) motifs, a motif known to be important for the association with nuclear receptors.
Belongs to the CNOT1 family.
研究領域
· Genetic Information Processing > Folding, sorting and degradation > RNA degradation.
Restrictive clause
Affinity Biosciences tests all products strictly. Citations are provided as a resource for additional applications that have not been validated by Affinity Biosciences. Please choose the appropriate format for each application and consult Materials and Methods sections for additional details about the use of any product in these publications.
For Research Use Only.
Not for use in diagnostic or therapeutic procedures. Not for resale. Not for distribution without written consent. Affinity Biosciences will not be held responsible for patent infringement or other violations that may occur with the use of our products. Affinity Biosciences, Affinity Biosciences Logo and all other trademarks are the property of Affinity Biosciences LTD.